by Florent IDARGO
Context
Hello!👋🏽
As one of the FLASS group member I will relate you our first achievements and our plans to monitor the next steps of
our project. We already have defined our strategy at the blog creation but as a quick reminder: our goal is to produce
arbitrage opportunities on listed video games studios through their video games trailers YouTube comments sentiments.
Sample Determination 📚
As we have the ambitious goal of predicting a stock price future trend, or at least develop a reliable indicator,
we needed first to get a training and a test sample. Video games studios are very diverse in their structure and
diversification. Even though they are listed, they have not intensively benchmarked each other’s management structures
and therefore maintain their strong, owns identities.
Front of this complex, international market, we have made the choice to build our data on the 25 most sold games of 2018,
making the assumption they were representative of the listed developers’ revenues and touch the main revenue sources.
To prevent corrupted data we’ve check one by one the linked game studios to understand any exogeneous event in the reveal
trailer publication period which might have biased the data. This made us eliminate few games that we replaced with lower
ranking game which fit our requirements.
Tool decision ♘
As 100% of our data come from YouTube, trying to scrape the Web site through libraries such as Scrapy would have been quickly denied by the platform as the number of requests would be too high. Although ways to bypass the rules a web site set in its robot.txt file exist, they look a bit shady/illegal, so we took another path, using the YouTube api.
Youtube API potential 🧙🏼♂️
Going for the YouTube api was our best choice. As we began to scroll through the official documentation it was certainly messy but the api already had a community of programmers, tutorials and external documentation. This was a precious asset and it allowed us to quickly get in the hard work of getting data to study the feasibility of our project.
Our necessity of getting things done was well supported by Alphabet’s structures which delivers credentials to its api service to each of its google accounts, without any delay. By this time we had every tool needed (documentation to learn and api key to implement) all that was left was to get the core job done: writing the software.
Software Development ⌨️
Data download limit
As we iterated through our game sample to collect their comments data, we faced a first issue, the downloading limit.
YouTube was only letting us download 10’000 comments per day, but most of our selected trailers had this amount of comments (note: the Youtube API only select the first comments, so it does not take into account the replies to a comment). Therefore, this would imply 25 days of data downloading, which is more than the time we have. As a compromise to this limit we have all decided to download every day the data from one game which allows us to get most of our YouTube data, going 5 time faster
Here just under a sample of the output we had on NBA 2K19, the emojis handling will be treated in future posts.
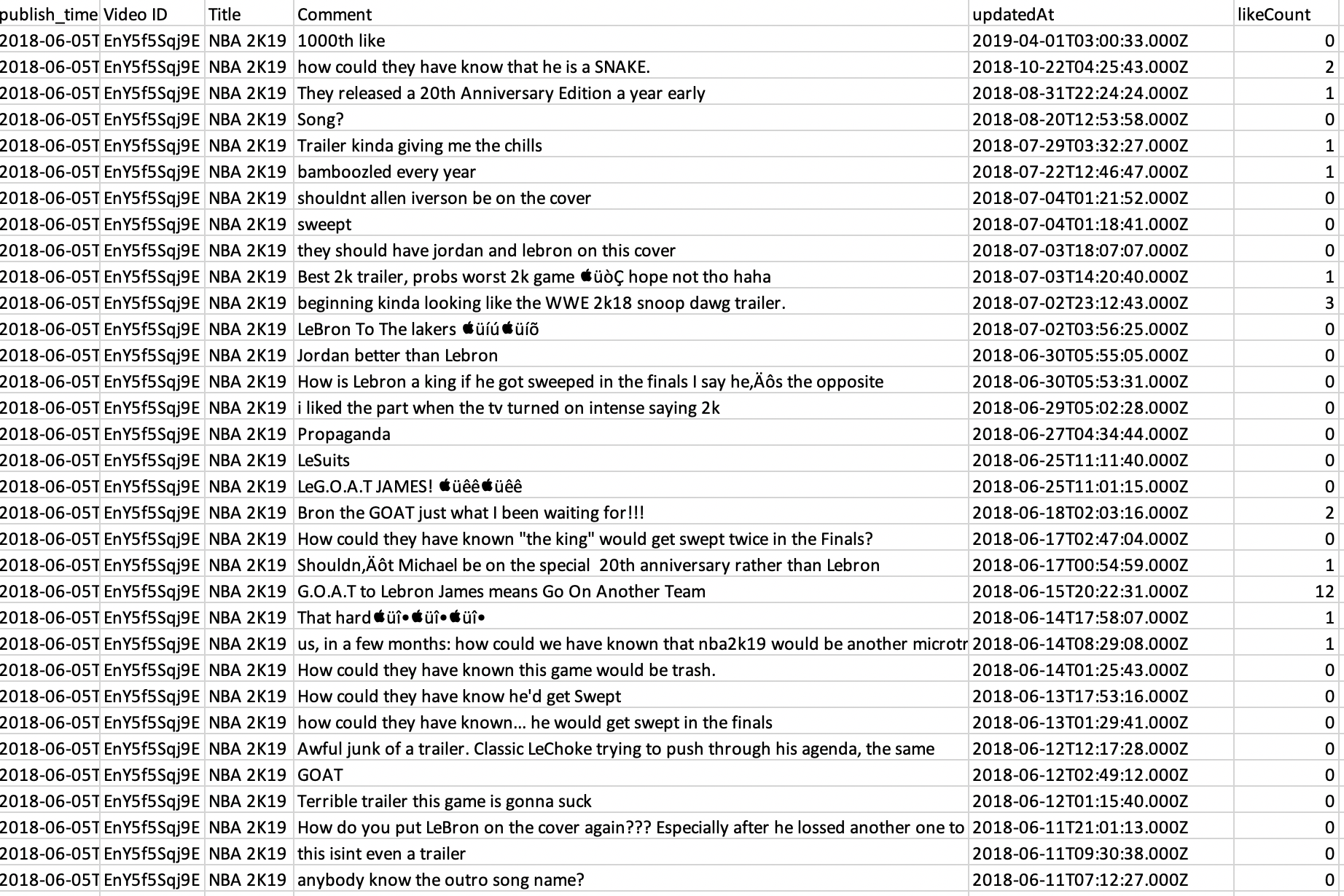
Videos’ Comments Heterogeneity
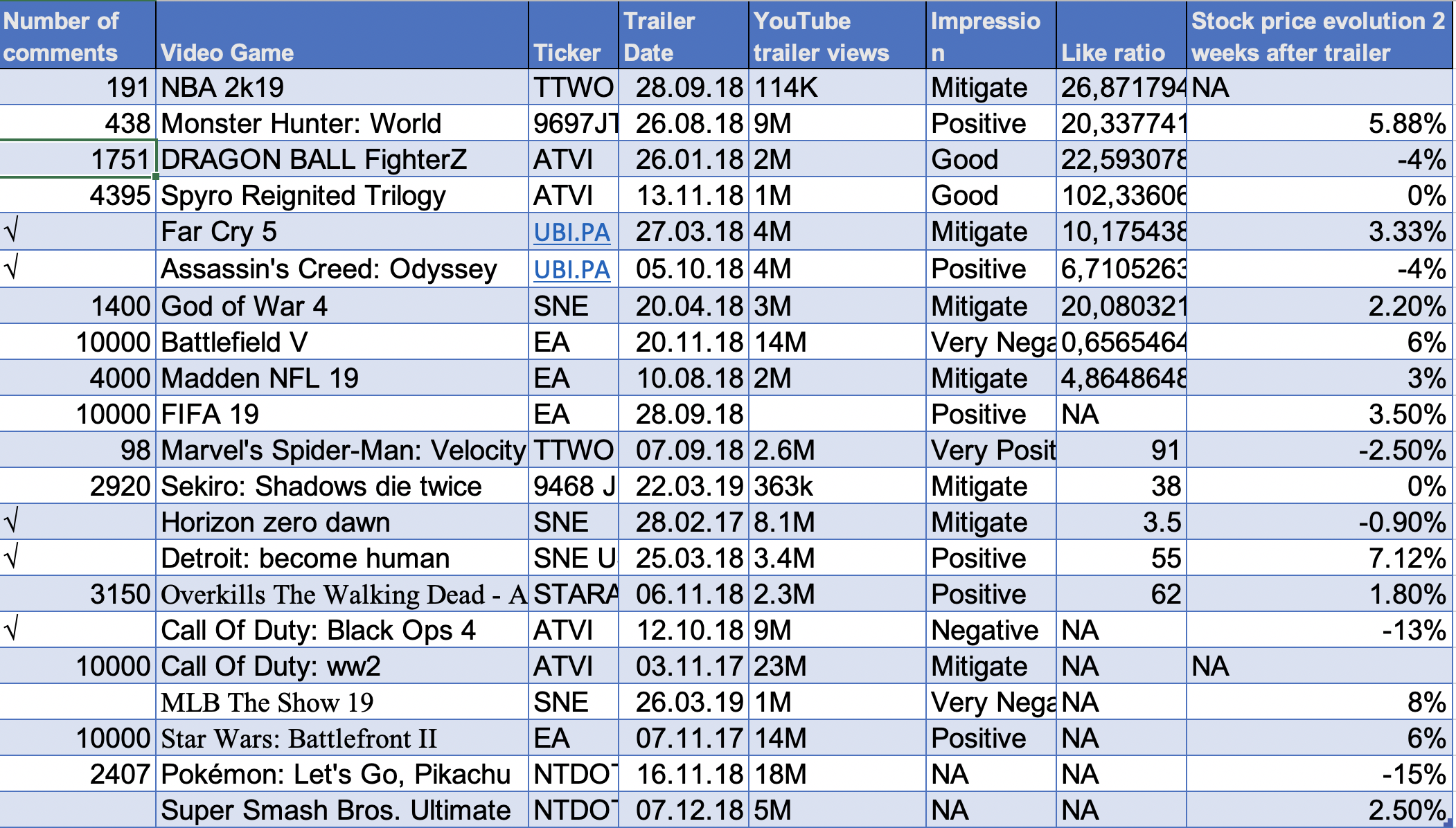
Our next issue was the heterogeneous quantity of comments under each reveal trailers. Most games have around 10’000 comments, one 40’000 comments and a few under 5’000…
We had two solutions: we could either weight each games’ sentiment output in our model according to its comments number, or we could take more videos from games having fewer comments.
The second solution seemed better as we are not yet statisticians, we could bias the result through computation mistakes and… As the adage says “garbage in -> garbage out” we need comparable games, if a game has too few comments it might be noise in our analysis.
Thus, games having less than 5’000 comments won’t be in our analysis and will be replaced by more commented trailer from 2018 games.
Coming work 📆
From our previous work we still need to complete our data with few more games compatible with our prerequisites… We expect to reach this work by the end of the week.
We will relate the text pre-processing and exploratory data analysis in our next blogpost.
Our last post will be about the mood learning and portfolio management.
Stay in touch with us !